Hash Function¶
A Hash Function compresses messages or data into digests, reducing the data size. Its general model is as follows:
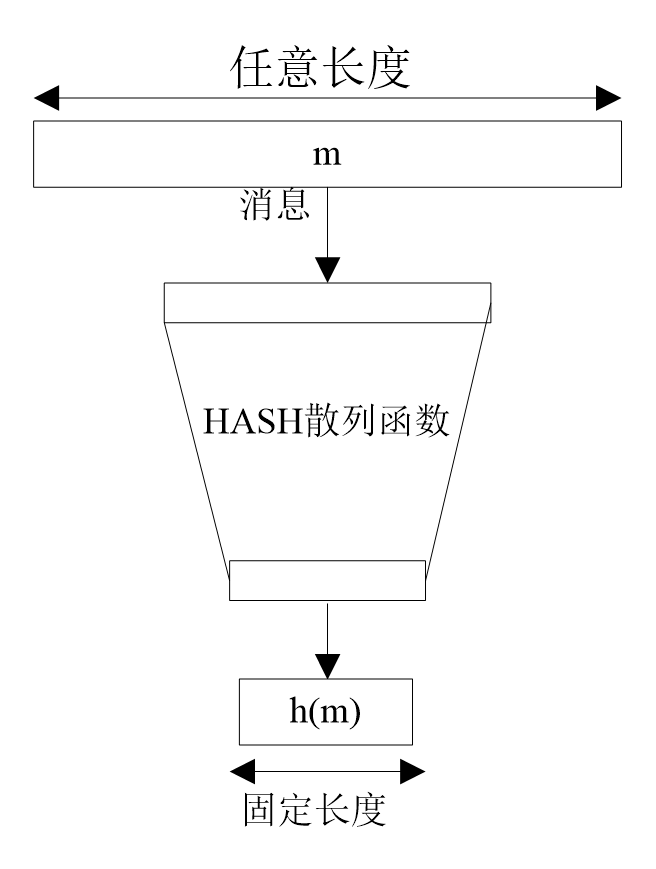
Obviously, for any given hash value, there theoretically exist several messages that correspond to it, i.e., collisions.
The basic requirements of a hash function are as follows:
| Requirement | Description |
|---|---|
| Variable input length | The hash function can be applied to data of any length |
| Fixed output length | The output length of the hash function is fixed |
| Efficiency | For any message x, computing H(x) is easy |
| One-wayness | For any hash value h, finding x such that H(x)=h is computationally infeasible |
| Weak collision resistance | For any message x, finding another message y such that H(x)=H(y) is computationally infeasible |
| Strong collision resistance | Finding any pair of messages x and y satisfying H(x)=H(y) is computationally infeasible |
| Pseudorandomness | The output of the hash function satisfies pseudorandomness test criteria |
The purposes of hash values are as follows:
- Ensure message integrity, i.e., ensure that the received data is indeed the same as when it was sent (i.e., no modification, insertion, deletion, or replay), preventing man-in-the-middle tampering.
- Redundancy checking
- One-way password files, such as passwords in Linux systems
- Signature detection in intrusion detection and virus detection
Currently, the main hash functions include MD5, SHA1, SHA256, and SHA512. Most current hash functions are iterative, i.e., they use the same hash function with different parameters for multiple iterations.
| Algorithm type | Output hash value length |
|---|---|
| MD5 | 128 bit |
| SHA1 | 160 bit |
| SHA256 | 256 bit |
| SHA512 | 512 bit |