I/O Virtualization¶
Real-world peripheral resources are often limited. Sometimes we don't need to let VMs directly access real physical peripherals, and sometimes we want to provide VMs with devices that don't have physical counterparts. Therefore, the Hypervisor needs to provide virtual device resources to VMs through I/O virtualization.
From the processor's perspective, our interaction with peripherals is mainly accomplished through MMIO and Port IO, hence the virtualization of peripherals is called I/O virtualization.
I/O virtualization needs to accomplish the following three tasks:
- Access interception: The Hypervisor needs to intercept the VM's access operations to peripherals.
- Providing device interfaces: The Hypervisor needs to provide virtual/passthrough device interfaces to VMs.
- Implementing device functionality: The Hypervisor needs to implement the functionality of virtual devices.
Basic Models¶
Platform device emulation¶
Platform device emulation means the Hypervisor is responsible for emulating the functionality of virtual devices. Different virtualization software implements emulated devices in different ways.
Hypervisor-based device emulation is a commonly used approach in VMware Workstation series products: the hypervisor contains emulations of common devices for sharing with guest OSes, including virtual disks, virtual network adapters, and other necessary elements. This model is shown in the figure below:
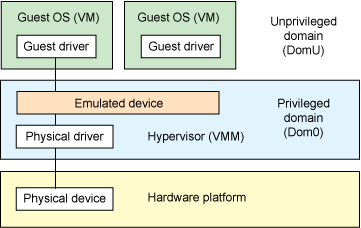
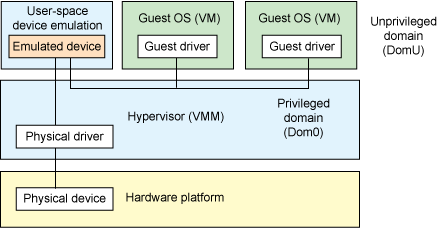
The second architecture is called User space device emulation, where the emulation of virtual devices takes place in user space. QEMU independently performs device emulation in user space, and virtual devices are invoked by other VMs through interfaces provided by the hypervisor. Since device emulation is independent of the hypervisor, we can emulate any device, and the emulated device can be shared among other hypervisors.
Device passthrough¶
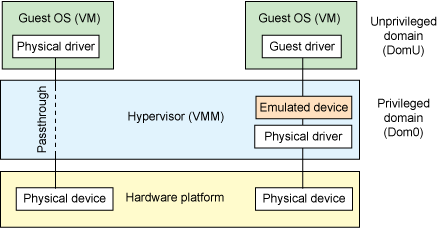
The two models above both have certain performance overhead to varying degrees. If the device needs to be shared among multiple VMs, this overhead may be worthwhile. However, if the device doesn't need to be shared, we can actually use a more efficient method — Device passthrough.
Device passthrough can be understood as device-exclusive device emulation: the device is directly isolated and assigned to a specific VM so that it can be exclusively used by that VM. This provides near-native device performance. For example, for devices that require heavy I/O (such as network devices), using device passthrough can provide nearly perfect performance.
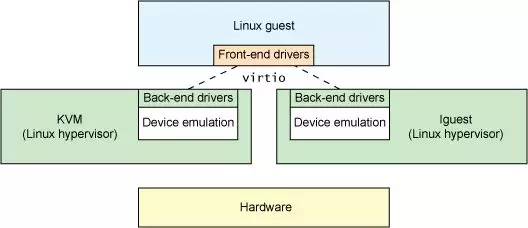
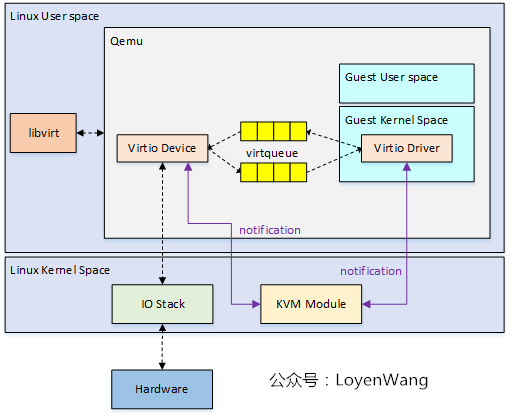
Software Para-virtualization - virtio¶
The concept of virtio comes from a very classic paper in the virtualization field: virtio: towards a de-facto standard for virtual I/O devices. It was mainly designed to solve the problem of device virtualization by providing a common virtualized device model. The Guest OS only needs to implement a unified set of virtio drivers to access virtualized devices in a uniform way, thus avoiding the problem of fragmented virtualization drivers.
VirtQueue: Transport Layer Abstraction¶
virtqueue is a key structure used for data transmission in virtio. It essentially represents a data queue: one side adds buffers to the queue, and the other side retrieves buffers from it — this implements a basic data transmission model between the Guest and Host.
To reduce model complexity, the transmission using virtqueue is typically unidirectional. Therefore, a simplest model uses two virtqueues to implement bidirectional communication between the Guest and Host: tx queue (transmit queue) & rx queue (receive queue).
The operations on virtqueue are abstracted in the paper as a function table virtqueue_ops:
struct virtqueue_ops {
int (*add_buf)(struct virtqueue *vq,
struct scatterlist sg[],
unsigned int out_num,
unsigned int in_num,
void *data);
void (*kick)(struct virtqueue *vq);
void *(*get_buf)(struct virtqueue *vq,
unsigned int *len);
void (*disable_cb)(struct virtqueue *vq);
bool (*enable_cb)(struct virtqueue *vq);
};
add_buf: Add a buffer to the virtqueuekick: Notify the other side that a new buffer has arrivedget_buf: Retrieve a buffer from the virtqueuedisable_cb: Notify the other side to disable buffer arrival notificationsenable_cb: Notify the other side to enable buffer arrival notifications
VRing: The Basic Structure of virtqueue¶
The core data structure of virtqueue is the vring, which is a ring buffer queue consisting of three parts:
- Descriptor table (Desc)
- Available descriptor array (Avail)
- Used descriptor array (Used)
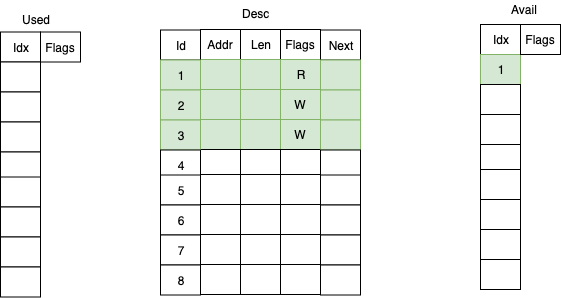
A descriptor has the following structure, representing the basic attributes of a buffer. Note that an Avail/Used entry is typically a buffer formed by chaining multiple descriptors — this is the purpose of the next field:
struct vring_desc
{
__u64 addr; // Guest Physical Addresses
__u32 len; // Length
__u16 flags; // Attributes
__u16 next; // Index of the next descriptor
};
The Avail array is used to store currently available descriptors:
struct vring_avail
{
__u16 flags;
__u16 idx;
__u16 ring[NUM];
};
The Used array is used to store descriptors that have been consumed:
struct vring_used_elem
{
__u32 id;
__u32 len;
};
struct vring_used
{
__u16 flags;
__u16 idx;
struct vring_used_elem ring[];
};
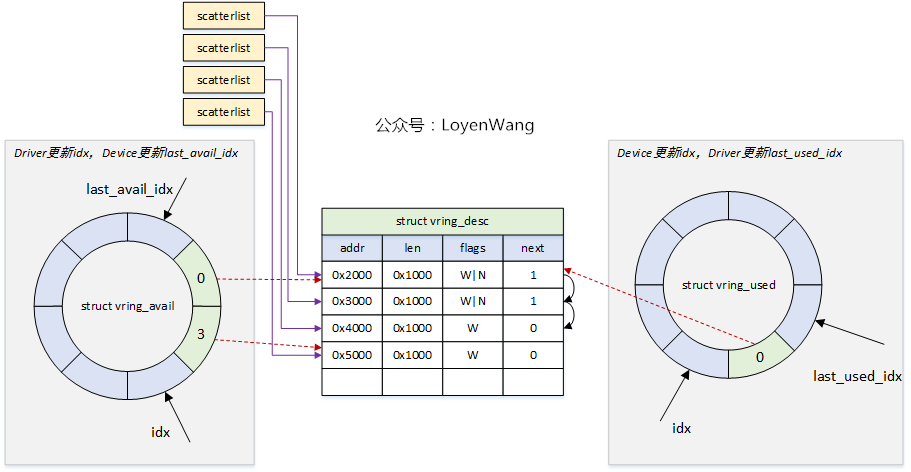
The Avail array and Used array are also ring queues, but these two arrays are used by the two communicating parties respectively:
- The data sender prepares the data, retrieves an available entry from the
Avail queue, updates the descriptor table, inserts a new entry into theUsed queue, and notifies the receiver that data has arrived. - The data receiver retrieves an entry from the
Used queue, reads the descriptor table to obtain the data, and after processing, inserts the entry back into theAvail queue.
The following figure shows an example of a vring for sending data from the Guest to the Host:
virtio Configuration Operation Abstraction¶
Combined with virtqueue, we can now abstract the basic operations of a virtual PCI device:
- Get feature bits
- Read/write configuration space
- Read/write status bits
- Device reset
- Create/destroy virtqueue
We abstract these into a function table: virtio_config_ops.
struct virtio_config_ops
{
bool (*feature)(struct virtio_device *vdev, unsigned bit);
void (*get)(struct virtio_device *vdev, unsigned offset,
void *buf, unsigned len);
void (*set)(struct virtio_device *vdev, unsigned offset,
const void *buf, unsigned len);
u8 (*get_status)(struct virtio_device *vdev);
void (*set_status)(struct virtio_device *vdev, u8 status);
void (*reset)(struct virtio_device *vdev);
struct virtqueue *(*find_vq)(struct virtio_device *vdev,
unsigned index,
void (*callback)(struct virtqueue *));
void (*del_vq)(struct virtqueue *vq);
};
feature: Get the corresponding feature bit of the device.get & set: Read/write the device's configuration space.get_status & set_status: Read/write the device's status bits.reset: Reset the device.find_vq: Get/create a virtqueue.del_vq: Destroy a virtqueue.
IOMMU¶
IOMMU stands for Input/Output Memory Management Unit. Its functionality is similar to the MMU in the CPU — it is a unit that provides address translation on the device side.
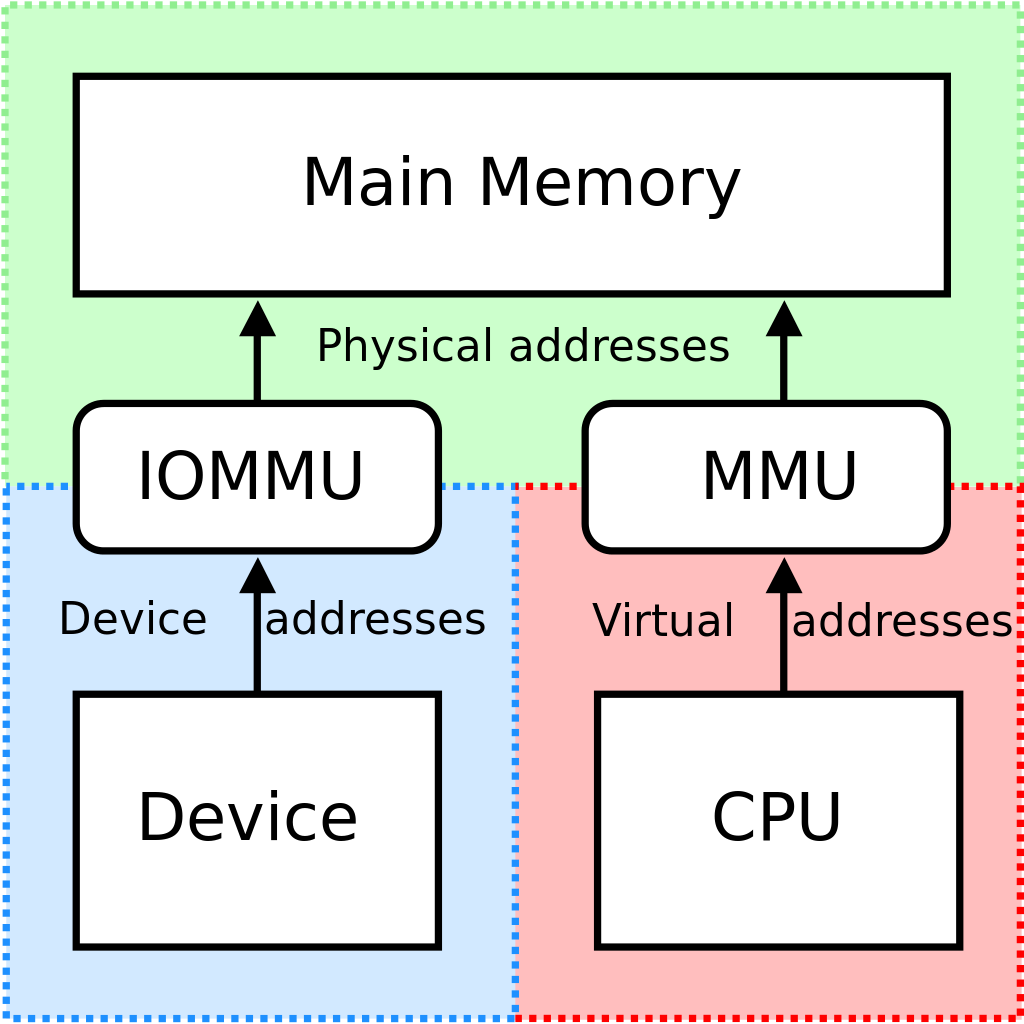
The IOMMU is typically integrated into the northbridge and provides two device-facing functions:
- DMA remapping: Devices with DMA capability can use virtual addresses, which are translated by the IOMMU into physical addresses for direct memory access.
- Interrupt remapping: The IOMMU intercepts interrupts generated by devices and produces new interrupt requests based on the interrupt remapping table, which are then sent to the LAPIC.
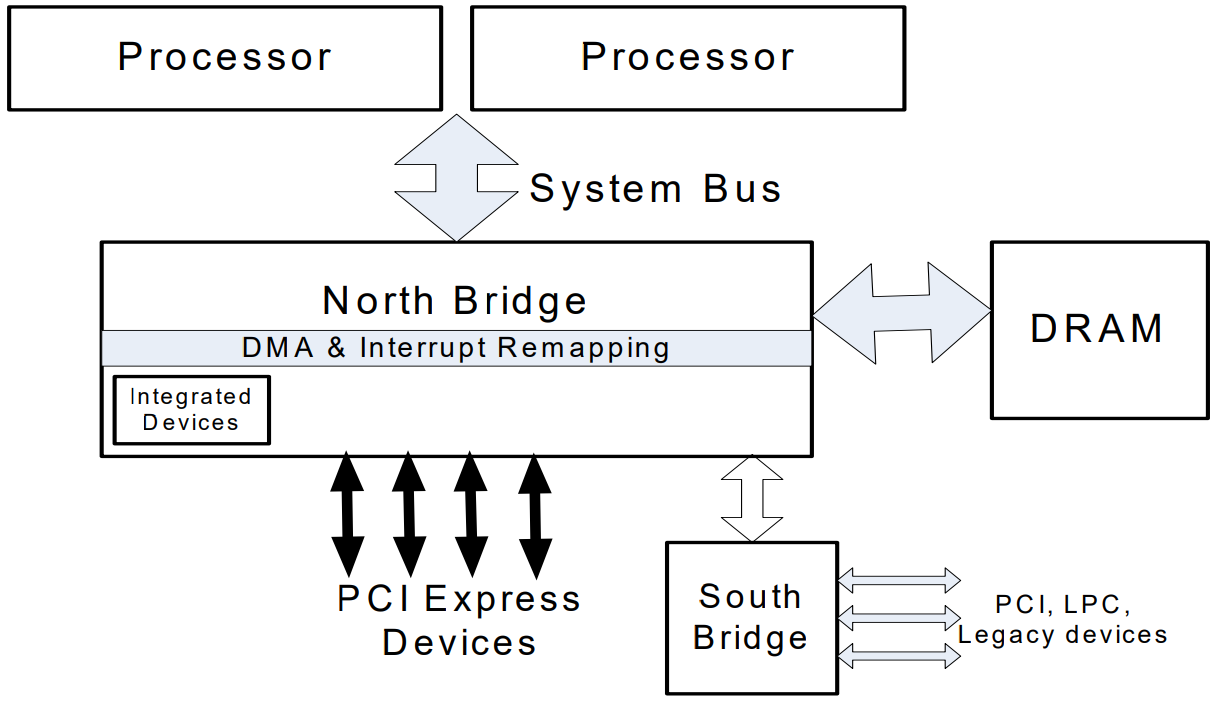
DMA Remapping¶
DMA remapping provides address translation on the device side. As shown in the figure below, the left side shows the CPU's memory virtualization: the MMU uses process page tables to translate the virtual addresses that processes want to access into physical addresses, enabling two processes to access the same virtual address but actually reach different physical addresses. DMA remapping works on a similar principle. As shown on the right side, when a peripheral wants to perform DMA, the IOMMU translates the address according to the "device page table", so that two devices each perceive they are accessing the same address, but they actually access different physical addresses.
![]()
IOMMU and Virtualization¶
Although the introduction of IOMMU adds overhead to peripheral communication, IOMMU solves a key challenge in system virtualization: for non-purely-emulated devices, they are unaware of the mapping between GPA and HPA. When they perform DMA using the address provided by the Guest OS, they directly access the Host's memory.
After introducing IOMMU, the IOMMU can perform DMA remapping based on the GPA-to-HPA address translation table provided by the Host side. This way, peripherals can correctly access the Guest's physical memory without erroneously accessing the corresponding physical memory region of the Host.
REFERENCE¶
IBM Archived | Linux virtualization and PCI passthrough
【Original】Linux Virtualization KVM-Qemu Analysis (Part 10) - virtio Driver
【Original】Linux Virtualization KVM-Qemu Analysis (Part 11) - virtqueue
virtio: towards a de-facto standard for virtual I/O devices
"System Virtualization — Principles and Implementation" — Intel Open Source Technology Center
A Tour Beyond BIOS: Using IOMMU for DMA Protection in UEFI Firmware