Memory Virtualization¶
Memory virtualization essentially needs to achieve the following two goals:
- Provide a contiguous physical memory space that starts from zero as perceived by the Guest.
- Effectively isolate, schedule, and share memory resources among different VMs.
Pure Software Memory Virtualization¶
VM Memory Access Principles and Challenges¶
To achieve memory space isolation, the Hypervisor needs to prepare a new layer of address space for the Guest VM: Guest Physical Address Space. From the Guest side, it can only see this layer of address space, and the Hypervisor needs to maintain the translation relationship from GPA to HVA.
The following figure shows the memory architecture of QEMU:
Guest' processes
+--------------------+
Virtual addr space | |
+--------------------+ (GVA)
| |
\__ Page Table \__
\ \
| | Guest kernel
+----+--------------------+----------------+
Guest's phy memory | | | | (GPA)
+----+--------------------+----------------+
| |
\__ \__
\ \
| QEMU process |
+----+------------------------------------------+
Virtual addr space | | | (HVA)
+----+------------------------------------------+
| |
\__ Page Table \__
\ \
| |
+----+-----------------------------------------------+----+
Physical memory | | | | (HPA)
+----+-----------------------------------------------+----+
When we want to access data at a virtual address within the Guest, we need to:
- First, translate the
Guest Virtual Address(GVA) to theGuest Physical Address(GPA) through the Guest's page table. - In QEMU's implementation, the GPA actually corresponds to a large mmap'd memory region on the Host, so we also need to translate the GPA to the
Host Virtual Address(HVA). - Finally, translate the HVA to the
Host Physical Address(HPA) through the Host's page table. - During multi-level page table address translation within the Guest, the
GPA→HPAtranslation process must also be performed multiple times.
This entire process is very expensive, resulting in extremely poor memory access performance in virtual machines.
In QEMU, the core function for memory access is
address_space_rw(), which implements theGPA→HVAtranslation. Interested readers can look at its internal implementation.
Shadow Page Table¶
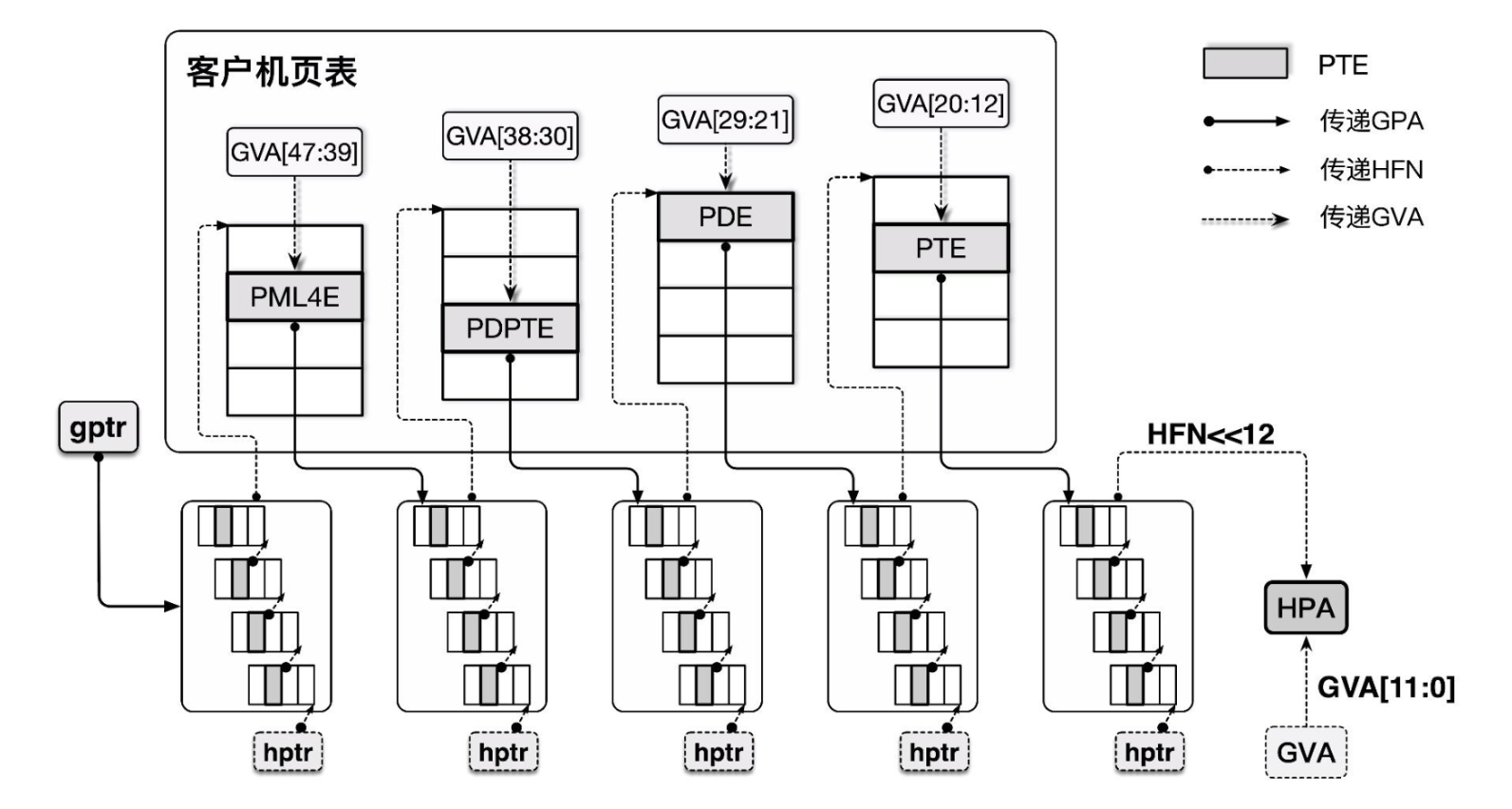
In the early days, Intel hardware did not have good support for virtualization, so the Hypervisor could only optimize at the software level first — the Shadow Page Table was born.
Taking Intel as an example, since the operation of reading/writing the CR3 register (which stores the top-level page table pointer) is a sensitive instruction, our Hypervisor can easily intercept the VM's operation and replace the page table with a shadow page table that stores GVA→HPA mappings, thus directly completing the GVA to HPA translation process.
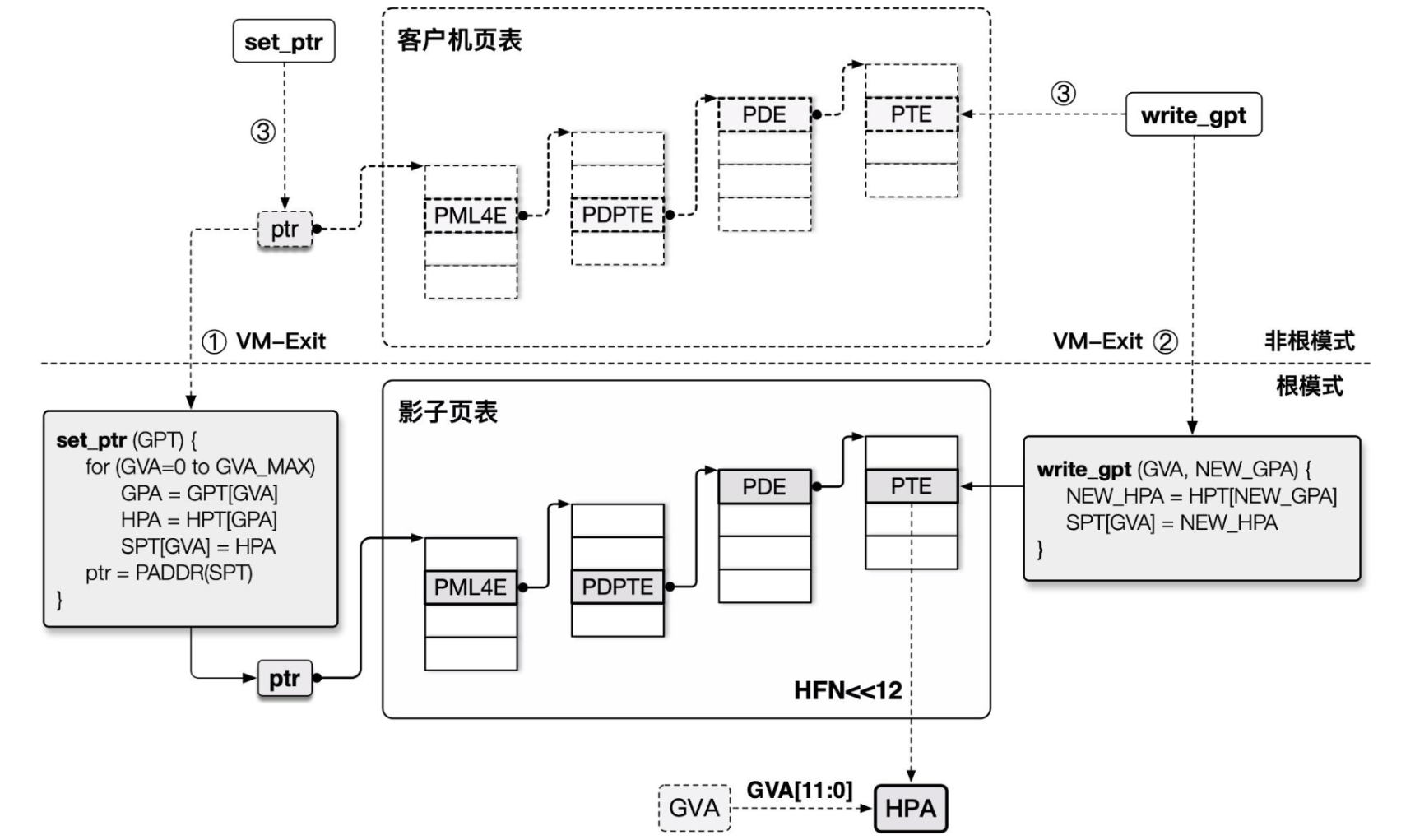
To implement the shadow page table, we essentially need to implement MMU virtualization:
- What the Guest VM can see and operate on is actually a virtual MMU. The page table actually loaded into the MMU is the shadow page table produced by the Hypervisor after translation.
- The access permissions in the shadow page table are read-only. When the Guest tries to read/write the page table, the Hypervisor can intercept the operation and handle it on behalf of the Guest.
However, the drawback of this approach is that we need to independently maintain a shadow page table for each set of page tables in the Guest VM, and multiple switches between the VMM and VM are required, which incurs significant overhead.
Hardware-Assisted Virtualization¶
Extended Page Table (EPT)¶
Optimization at the software level seems to have reached its limits, so hardware-level support for memory virtualization was born — EPT, or Extended Page Table, is a feature added by Intel for memory virtualization, aiming to reduce memory access overhead.
EPT does not interfere with the Guest VM's own page table operations. It essentially provides an additional page table for translating Guest physical address space to Host physical address space, i.e., it uses an additional page table to complete the GPA→HPA translation.
Although the EPT approach has one more level of translation compared to shadow page tables, it does not need to interfere with the Guest's original page table management. The GVA→GPA→HPA process is all completed automatically by hardware, and the Hypervisor only needs to intercept EPT Violation exceptions (when EPT entries are empty), which significantly improves efficiency.
VPID: TLB Resource Optimization¶
The Translation Lookaside Buffer is a page table entry cache used to accelerate virtual-to-physical address translation. When performing address translation, the CPU first queries the TLB, which looks up whether there is a corresponding cache entry based on the virtual address. Only on a cache miss does it query the page table.
Since the TLB works in conjunction with the corresponding page table, when the page table is switched, the existing TLB contents become invalid, and we should use INVLPG to invalidate the TLB. Similarly, during VM-Entry and VM-Exit, the CPU forcibly invalidates the TLB. However, this still incurs some performance loss.
Virtual Processor Identifier (VPID) is a hardware-level optimization for TLB resource management. It tags each TLB entry with a VPID identifier at the hardware level (the VMM assigns a unique VPID to each vCPU, stored in the VMCS; the logical CPU's VPID is 0). When the CPU looks up the TLB cache, it first compares the VPID. This way, we don't need to flush all cache entries on every VM entry/exit, and can continue reusing previously retained cache entries.
REFERENCE¶
"System Virtualization: Principles and Implementation" — Intel Open Source Technology Center
【VIRT.0x02】Introduction to System Virtualization
"Deep Exploration of Linux System Virtualization" — Wang Baisheng, Xie Guangjun